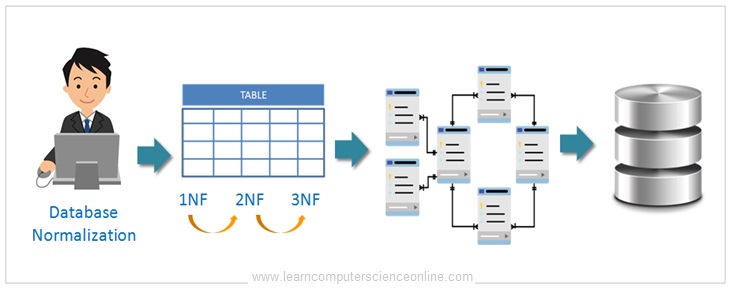
The database normalization is the process of organizing the database structure by splitting up the larger tables into smaller but meaningful tables.
The database is an important component of the software projects where the database operations are required. The efficiency and the accuracy of the software application depends upon the database performance.
The database design involves number of activities. During the database design process, the database designers aim to build the database that is robust and stores the data in most efficient manner.
The database normalization is an important step which helps the database designers to eliminate the duplication of data which leads to database anomalies .
In this tutorial , you will learn what is database normalization , why do we need to normalize the database , how database normalization is done step by step .
Further , we will also discuss the database normalization standards 1NF, 2 NF, 3NF as defined by E F Codd and boyce Codd 4NF , 5 NF BCNF normal forms.
What Is Database Normalization ?
Database normalization is a systematic process in database design that organizes data into multiple related tables to reduce redundancy and improve data integrity. The primary objective of normalization is to decompose larger, complex tables into simpler, smaller tables without losing any data, ensuring that each table focuses on a single topic or entity.
This process involves applying a series of rules, known as normal forms, which progressively eliminate redundancy and potential anomalies in data operations such as insertion, update, and deletion. The main normal forms, from the first normal form (1NF) to the fifth normal form (5NF), each address specific types of redundancy and dependency issues
Before we start the discussion on database normalization , let us get familiar with the term data and database in the context of database systems.
What Is Data In DBMS ?
In database world , the term data means raw data which mainly includes facts , figures , set of values and scientific observations . The is usually collected in its raw form which makes it unusable for any meaningful application.
And therefore , the data needs to first scientifically collected and recorded so that it can be digitally processed with the help of any computer system.
The raw data is processed using a computer system and a computer program used to operate on the data . The data is converted into information after being processed .
So , we can say information is a processed data that can be used for some meaningful work . The computer program defines the instructions to operate on the data .
What Is Database In DBMS ?
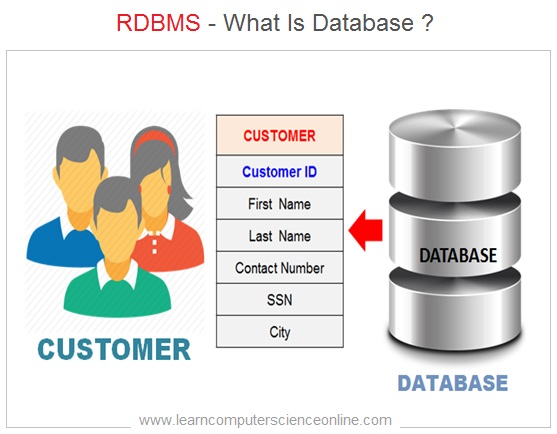
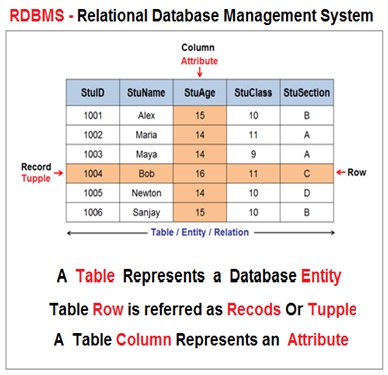
In the context of Database Management System , A database is defined as systematic and well-organized collection of data , information that can be digitally processed.
The database allows the efficient storage of data and define the relationship between various data elements . So, we can say , the database is an organized collection of interrelated data.
What Is Database ?
What Is Database ?
The data can be efficiently stored into the database. And therefore , the data can be easily accessed , retrieved , manipulated by performing various database operations .
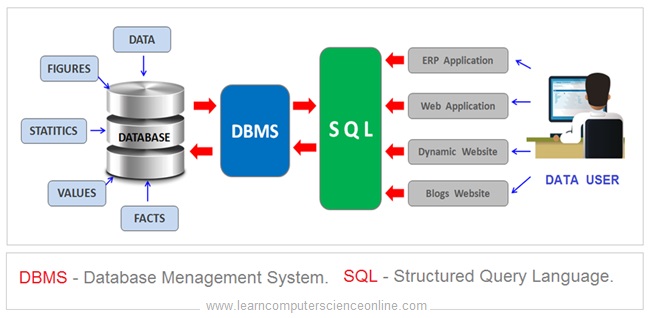
The Database Management System ( DBMS ) is a software application used to create and manage the databases. The DBMS works as an interface between the front end software application and the database.
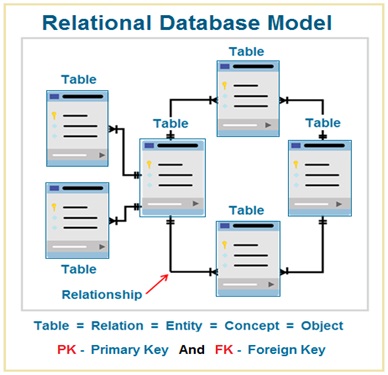
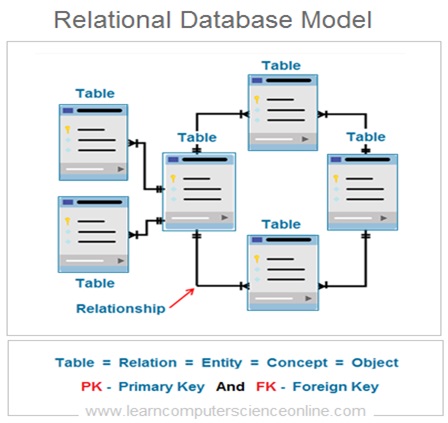
Database Normalization
Relational Database Structure
The term database normalization is used in the context of relational database. The normalization process is used during database design process to ensure consistency and the accuracy of the data.
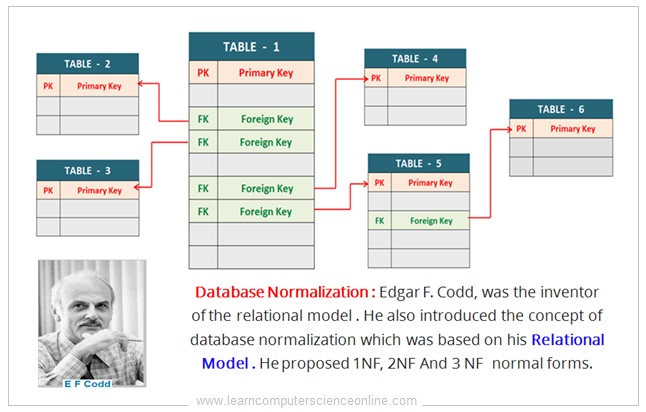
A relational database is a type of database that is based on the relational model . The relational model was invented and proposed by British computer scientist E F Codd.
Relational Model
Relational Model
As per the relational database model , the logical structure of the database consist of number of interrelated tables . The relationship between the tables is created by defining the primary and foreign key.
The relational database structure is normalized by decomposing the tables as per the set of rules defined by E F Codd . The relational database is normalized by applying the database normalization rules.
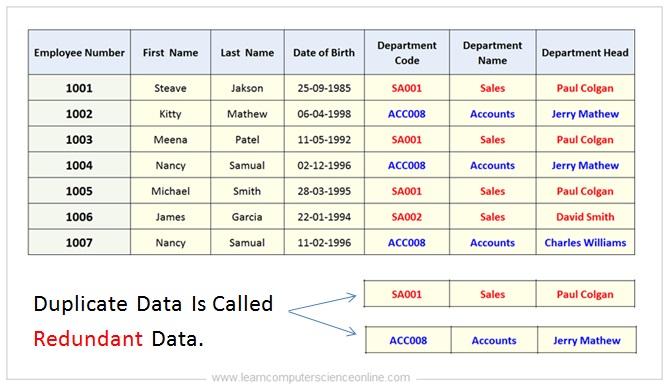
Data Redundancy
Problems Without Database Normalization
The duplication of data at multiple places in the database table is called redundant data . It is the root cause of many potential problems which needs to be treated with the database normalization.
A table is a representation of the database entity. In relational database model , the logical structure of the database consist of number of interrelated tables.
However , it is important to organize the table structure while designing the relational database. If the data organized into few large tables then it creates many potential problems.
Example Of Data Redundancy
One of the most common problem related to the large tables ( un-normalized table ) is the presence of duplicate data. The duplicate data in a table can cause database anomalies.
The presence of duplicate data at multiple places in a table is also referred as data redundancy and the duplicate data is referred as redundant data.
The duplication of data in a table and the consequential database anomalies is the most common cause of the inconsistent state of the database .
The inconsistent state of the database results into inaccurate results for various database queries and adversely affect the various database operations.
And therefore , the database structure must be normalized during the database design process to avoid any potential problem.
Database Normalization
Database Anomalies
The database anomalies are the problems that can cause inconsistent state of the database and produce wrong results for various database operations. The duplicate data at multiple places is the most common problem in the large table that stores the data related to more than one entity. Such large tables without normalization will have duplicate data that can create many potential problems if not treated properly.
Database Anomalies
Database Anomalies
The database anomalies are the problems caused due to the presence of duplicate data ( redundant data ) in the large tables. The database anomalies is the root cause of inconsistent state of the database .
The database queries and operations fail to produce the correct results due the inconsistent state of the database caused by various database anomalies.
Types Of Database Anomalies
There are three types of database anomalies triggered by the duplicate records typically in the un-normalized table . These database anomalies are :
The database queries and operations fail to produce the correct results due the inconsistent state of the database caused by these database anomalies.
Insertion Anomaly
Deletion Anomaly
Update Anomaly
What Is Insertion Anomaly ?
The insertion anomaly does not allow insertion of data unless it is accompanied by other unrelated data . The insertion anomaly is caused due to presence of redundant data in a table. Let us consider one example of student table. An insertion anomaly will be created If we combine the both student details and course enrolled in a single table.
Due to insertion anomaly , it is necessary to add the course details each time a new student is added to the database and that should not be the case.
What Is Deletion Anomaly ?
The deletion anomaly is also caused due to the data redundancy problem in the database table. Due to deletion anomaly , the database deletion operation also unintentionally deletes other data and can cause loss of important data.
For example, consider the same student table that combines the information related to the students details and the course enrolled. The deletion anomaly will be created and the course related data will also be permanently deleted for the course with single student.
What Is Update Anomaly ?
The update anomaly is also caused due to the presence of redundant data in the database table . The update anomaly is also referred as modifying anomaly. Due to update anomaly , the database update operation fails to modify all the records and this incomplete update operation results into the inconsistent state of the database.
For example, consider the same student table that combines the information related to the student details and the course enrolled. The update anomaly will be created when the database update operation fails to update the change of course duration for all the students enrolled for that course.
Database Normalization
What Is Database Normalization ?
The database normalization is defined as the process of organizing the large database tables into smaller but more relevant tables in order to eliminate the problems caused due to data redundancy.
The main objective of the database normalization is to minimize the presence of redundant data in various tables that causes database anomalies.
The normalization is achieved by decomposing the larger tables that combines data of the multiple entities . These large tables are split into small tables that contains data of the single entity.
The relationship between the tables is established by defining the primary key and the foreign key for each table.
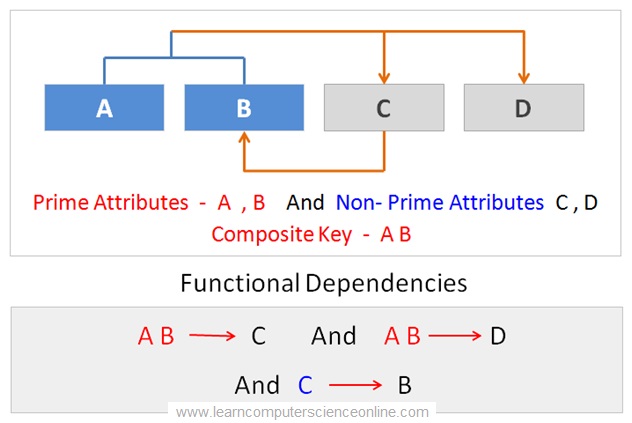
The normalization works on the principle of minimizing the functional dependencies and the functional segregation of data for each database entity.
Database Normalization
How To Normalize Database ?
The normalization technique is applicable to the relational databases. The database normalization is done by applying the normalization standards as defined by E F Codd in his relational model.
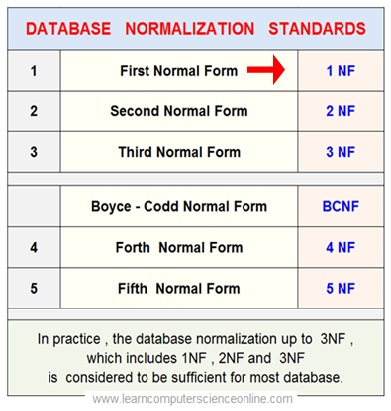
E F Codd was the inventor of the database normalization rules and he proposed the concept of first normal form ( 1NF ) , second normal form ( 2NF ) and the third normal form ( 3NF ).
The E F Codd normalization standards are applied during the database design process to eliminate the data redundancy in relational tables and the database anomalies.
Normalization Rules
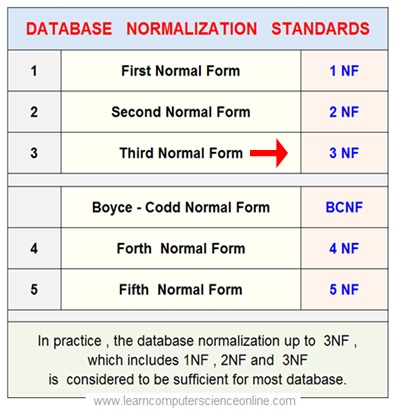
Database Normalization Standards
The inventor of relational database model Edgar F Codd introduced the concept of database normalization in order to eliminate the database anomalies.
He proposed three stage database normalization process in terms of three normal forms which database relational tables must comply
Most databases anomalies can be removed by normalizing the database tables up to the third normal form. However , some databases needs to be further treated to eliminate the remaining anomalies.
E F Codd subsequently joined Raymond F Boyce and both jointly developed the Boyce-Codd Normal Forms ( BCNF ).
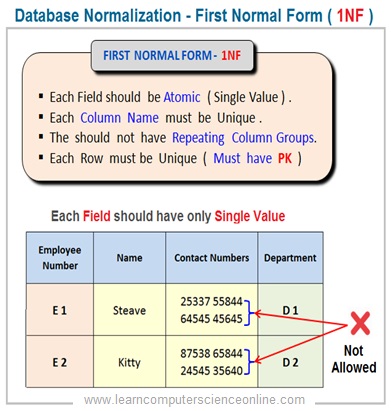
As per E F Codd criterion for the relational table to be in the first normal form the table must satisfy the following normalization rules :
Each table cell should have atomic value.
Each column ( attribute ) name should be unique.
No repeating column groups allowed.
Table must have a primary key.
First Normal Form
First Normal Form
Database Normalization
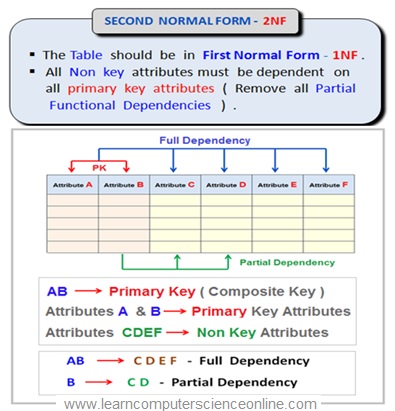
Second Normal Form ( 2NF )
As per E F Codd criterion for the relational table to be in the second normal form the table must satisfy the following normalization rules :
The table must be in the first normal form.
The table should not have any partial dependencies.
Second Normal Form
Second Normal Form
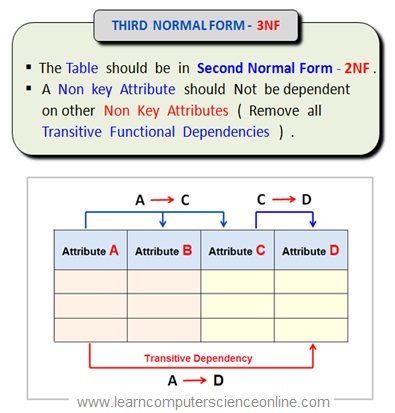
Third Normal Form ( 3NF )
As per E F Codd criterion for the relational table to be in the third normal form the table must satisfy the following normalization rules :
The table must be in the second normal form.
The table should not have any transitive dependencies.
Third Normal Form
Third Normal Form
Database Normalization
Boyce - Codd Normal Form ( BCNF )
The main objective of the normalization process is to remove the data redundancy in a relational tables.
The three normal forms ( 1NF , 2NF , 3NF ) can eliminate most of the redundancy problems caused due to functional dependencies.
The BCNF standard is a higher version of third normal form ( 3NF ). The BCNF was developed to handle the remaining redundancies that may still exist in the database.
The BCNF was jointly developed by an English Computer Scientist E F Codd and Raymond F Boyce who was an American computer scientist. The BCNF was developed to remove the data redundancy that still exists even after normalization to the third normal form ( 3NF ).
The BCNF normalization can effectively handle the redundancies caused due to multiple overlapping candidate keys.
Rules For BCNF
The table should be in the third normal form ( 3NF ).
For functional dependency A --> B , A should be a Super key.
Database Normalization Example
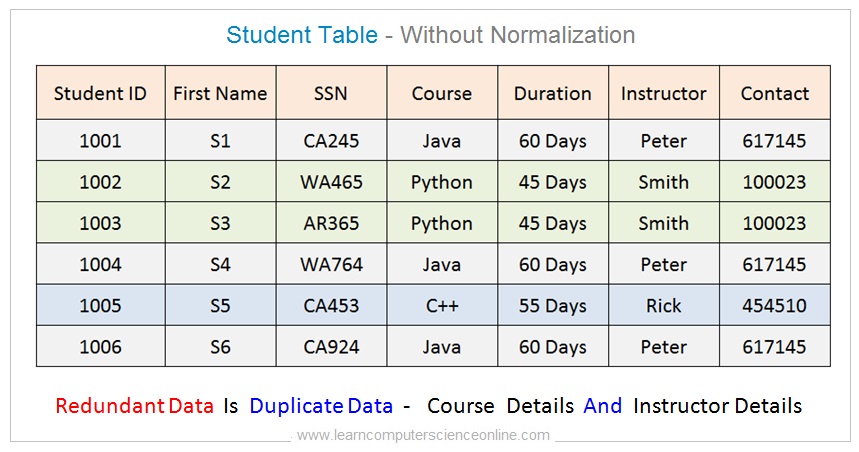
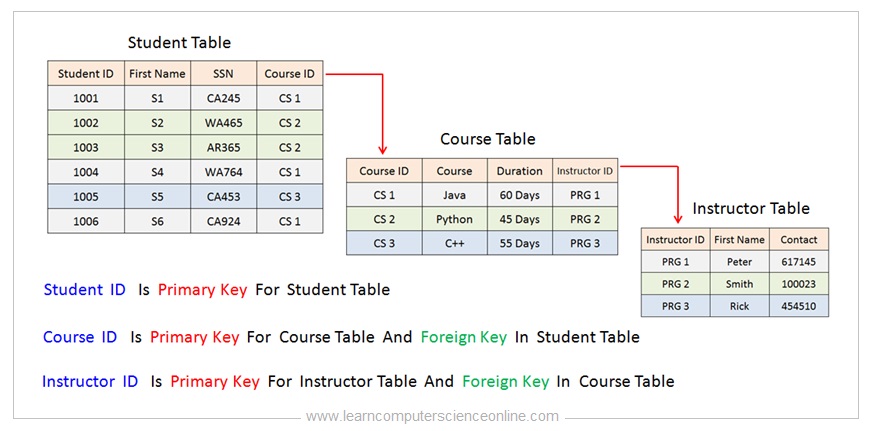
In order to illustrate the normalization process , let us consider one simple example. This is a single table database .
This table contains the information about the student , course enrolled by the student and the instructor details for each course. This table contains the data of three database entities. The three entities are , first the student, second the course enrolled, and the third entity is instructor.
The problem with this table is the multiple duplicate data. This table contains duplicate data ( redundant data ) in the multiple records. For example, the course enrolled by each student and the instructor details are present in multiple records as redundant data.
In order to normalize this table, we need to create a separate table for each database entity ( Student Table , Course Table , Instructor Table ) and then define the primary key for each table.
Depending upon the functional dependencies , the relationship between the tables needs to be defined using primary key and foreign key constrains.
The Course Table contains Course ID as primary key field. The Course ID field has been included in the student table as a foreign key.
Similarly , the Instructor table contains Instructor ID as primary key field. This Instructor ID field has been included in the Course Table as a foreign key.
After completing the normalization process , the data redundancy problem has been eliminated in all the three tables.
Since the data redundancy problem is now resolved after normalization , the database anomalies problems caused due to the presence of redundant data are also now stands resolved.