

Data Science
What Is Data Science ?
Introduction To Data Science
Beginners complete guide to the basics of data science , what is an data science, how to become data scientist, types of DS processes.
Introduction To Data Science
Data science is a multidisciplinary field that involves extracting insights and knowledge from data through a combination of statistical and computational methods. It involves using techniques from mathematics, statistics, computer science, and domain-specific knowledge to process, analyze, and interpret large and complex data sets.
The goal of data science is to provide actionable insights that can be used to solve business problems or to gain new insights into scientific phenomena. Data scientists use a variety of tools and techniques, including machine learning algorithms, statistical models, data visualization tools, artificial intelligence and data mining techniques to explore and analyze data.
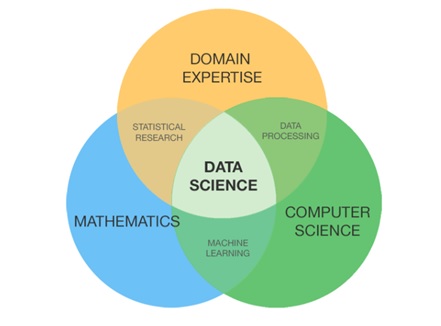
Data science is used in a variety of fields, including finance, healthcare, marketing, space research military science and social media. It has become increasingly important in recent years due to the explosion of digital data and the increasing use of machine learning algorithms to automate decision-making processes.
The data science market is a rapidly growing industry, with estimates of its size varying depending on the source and scope of the definition. According to a report by Grand View Research, the global data science market size was valued at USD 14.16 billion in 2020 and is expected to grow at a compound annual growth rate (CAGR) of 30.0% from 2021 to 2028. The report predicts that the market will reach a value of USD 274.3 billion by 2028.
What Is Data Science ?
Data science is an interdisciplinary field that involves the use of statistical and computational methods to extract insights and knowledge from data. It combines aspects of statistics, mathematics, computer science, and domain-specific knowledge to analyze and interpret complex data sets.
Data scientists use a variety of tools and techniques to analyze data, including data mining, machine learning, and predictive modelling. They may also work with large datasets, often referred to as “big data,” to develop algorithms and models that can identify patterns and make predictions based on data.
Data science is used in a wide range of industries, including healthcare, finance, marketing, and government. It plays a critical role in helping organizations make data-driven decisions and gain insights into complex problems.
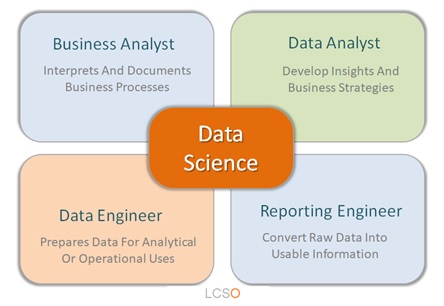
Data science is a multidisciplinary field that involves using scientific methods, processes, algorithms, and systems to extract knowledge and insights from structured and unstructured data. It encompasses a range of technical and analytical skills, including statistics, machine learning, programming, and data visualization.
The primary goal of data science is to make sense of the vast amounts of data generated by businesses, governments, and individuals. Data scientists use a variety of tools and techniques to clean, transform, and analyze data, with the aim of uncovering patterns, trends, and insights that can inform decision-making.
Definition Of Data Science
Data science is a field that involves the use of scientific methods, processes, algorithms, and systems to extract knowledge and insights from structured and unstructured data. It combines elements of statistics, mathematics, computer science, and domain-specific knowledge to identify patterns, trends, and relationships within data, and to use these insights to inform decision-making.
The goal of data science is to provide a data-driven approach to problem-solving, allowing businesses and organizations to optimize their operations and improve outcomes.
What Is Data ?
It is important to understand the meaning of term ‘Data’ in the context of data science.
Data refers to any collection of facts, figures, statistics, or other pieces of information that can be stored, processed, and analyzed using various methods and tools. Data can take many different forms, including text, numbers, images, audio, video, and more.
Data is typically organized in a structured or unstructured format and can be stored in various types of digital or physical storage media, such as databases, spreadsheets, files, and hard drives.
In today’s digital age, data is becoming increasingly important as it is used to drive business decisions, inform research and analysis, and provide insights into various aspects of society and the world. The ability to collect, process, and analyze data has become a crucial skill for individuals and organizations across all industries.
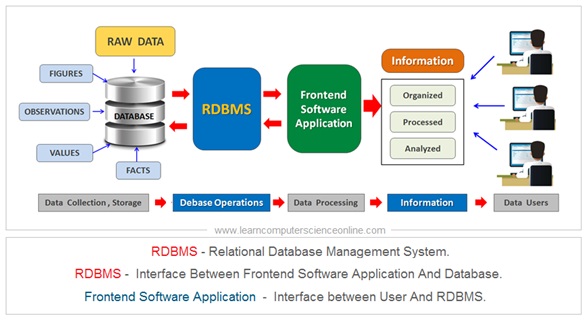
Introduction To Data Science
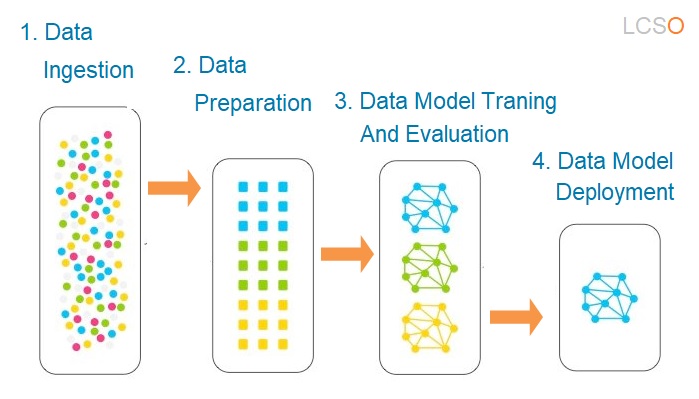
Data Science Process
The data science process is a systematic approach to solving problems using data. It involves a series of steps that are designed to extract insights and knowledge from data. The process typically involves the collection, preparation, analysis, and interpretation of data using statistical and machine learning techniques.
The data science process is typically used to solve complex problems that involve large amounts of data. By following a structured process, data scientists can ensure that their analysis is thorough and unbiased, and that their conclusions are based on solid evidence.
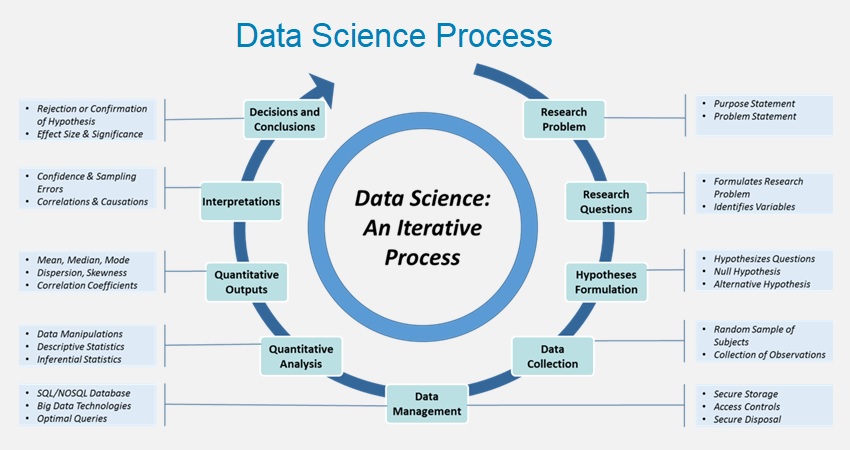
The data science process can be used in a variety of fields, including business, healthcare, finance, and government. It is a valuable tool for organizations that want to make data-driven decisions and gain a competitive advantage in their industry.
The data science process is a powerful methodology that can help organizations extract insights from their data and make informed decisions based on evidence rather than intuition.
The data science process typically consists of several stages, including:
1. Problem Formulation
Problem formulation is a critical first step in any data science project. It involves defining the problem or question that you want to answer using data. The process of problem formulation is a key component of the overall data science process, as it sets the foundation for the entire project.
The first step in problem formulation is to understand the business context. This involves understanding the goals and objectives of the organization, as well as the specific problem or challenge that you are trying to solve. For example, if you are working for a retail company, you may be asked to analyze customer data to identify patterns in buying behavior that can help the company increase sales.
Once you have a clear understanding of the business context, the next step is to identify the key stakeholders in the project. This includes identifying who will be using the results of your analysis, as well as any other stakeholders who may be impacted by the project. For example, in the retail example above, stakeholders may include sales teams, marketing teams, and senior management.
2. Data Collection
Data collection is a critical step in the data science process. It involves gathering data from a variety of sources in order to answer the problem or question that was defined in the problem formulation stage. The quality and completeness of the data collected can have a significant impact on the accuracy and effectiveness of the final analysis.
There are many different sources of data that can be used in a data science project, including structured data from databases, unstructured data from text documents, and data from web scraping or APIs. The data can be collected from internal sources within an organization, or from external sources such as public databases or social media platforms.

One important consideration in data collection is to ensure that the data is relevant to the problem being solved. This means that the data collected should be focused on the variables that are most relevant to the problem statement. It’s also important to ensure that the data collected is of sufficient quantity and quality to support the analysis.
Data collection can be a time-consuming and resource-intensive process, and it’s important to have a clear plan in place before starting. This includes identifying the data sources, defining the data collection process, and establishing protocols for data quality and security.
3. Data Preparation
Data preparation is a critical step in the data science process that involves cleaning, transforming, and organizing the data in a way that makes it suitable for analysis. This stage is important because the quality and accuracy of the data used can significantly impact the accuracy and effectiveness of the final analysis.
The first step in data preparation is to clean the data. This involves identifying and correcting errors or inconsistencies in the data, such as missing values, duplicates, and outliers. Data cleaning is essential to ensure that the data is accurate and reliable.
The next step is to transform the data. This involves converting the data into a format that is suitable for analysis. For example, this may involve converting categorical data into numerical data or scaling the data to a common range. Data transformation is important because it can help to uncover patterns and relationships in the data that may not have been visible before.
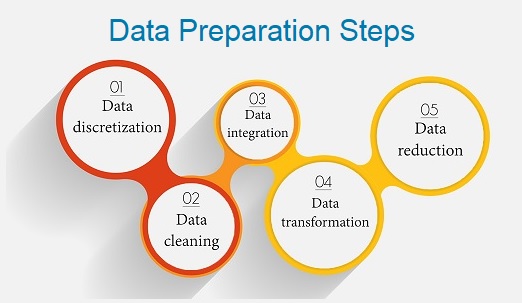
Once the data has been cleaned and transformed, it needs to be organized in a way that is suitable for analysis. This may involve splitting the data into subsets, merging data from different sources, or aggregating data at different levels of granularity. Data organization is important because it can help to ensure that the data is organized in a way that facilitates analysis and makes it easy to interpret the results.
Finally, data preparation may involve creating additional features or variables that can be used in the analysis. This may involve combining existing variables or creating new variables based on domain knowledge or intuition. Feature engineering is an important aspect of data preparation because it can help to uncover patterns and relationships in the data that may not have been visible before.
4. Data Exploration
Data exploration is an essential step in the data science process that involves analyzing and visualizing the data to gain a better understanding of its characteristics, relationships, and patterns. This stage is important because it can help to identify trends and patterns in the data, as well as potential outliers or anomalies that may need to be addressed in subsequent analysis.
The first step in data exploration is to generate descriptive statistics to summarize the data. This may include calculating measures of central tendency, such as mean, median, and mode, as well as measures of dispersion, such as standard deviation and range. Descriptive statistics can help to identify patterns in the data and provide a baseline understanding of its characteristics.
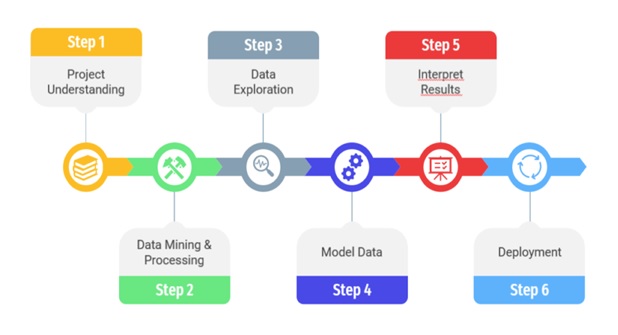
Next, data scientists may use data visualization techniques to explore the data visually. This may include creating histograms, scatter plots, and box plots to visualize the distribution of the data and identify potential outliers or anomalies. Visualization can be particularly useful when working with large datasets because it can help to identify patterns and relationships that may not be apparent from descriptive statistics alone.
Data exploration may also involve applying statistical techniques to test hypotheses or identify relationships between variables. This may include conducting correlation analyses, regression analyses, or clustering analyses to identify patterns or groupings in the data. By using statistical techniques, data scientists can gain a deeper understanding of the data and develop hypotheses that can be tested in subsequent analyses.
Finally, data exploration may involve identifying missing or incomplete data and developing strategies to address these gaps. This may include imputing missing values or dropping variables with a high percentage of missing data. By addressing missing or incomplete data, data scientists can ensure that their analysis is based on a complete and accurate dataset.
5. Data Modeling
Data modeling is a critical step in the data science process that involves developing mathematical or statistical models that can be used to make predictions or gain insights from the data. The goal of data modeling is to create a model that accurately represents the underlying relationships and patterns in the data and can be used to make predictions or inform decision-making.
The first step in data modeling is to select an appropriate modeling technique based on the problem and the nature of the data. This may involve selecting from a range of techniques, such as linear regression, logistic regression, decision trees, or neural networks. The choice of modeling technique will depend on the specific problem and the type of data available.
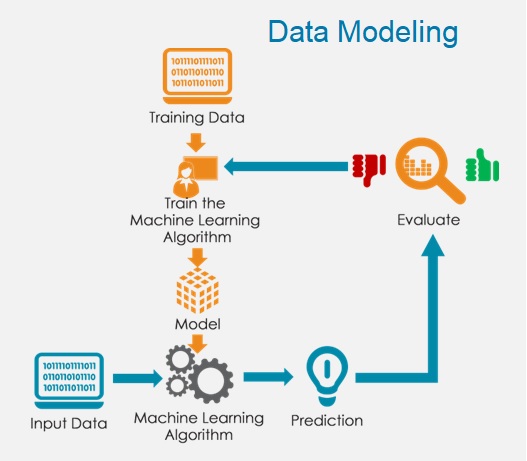
It’s important to note that data modeling is an iterative process. Data scientists may need to revisit earlier stages of the process, such as data preparation or data exploration, if the model is not performing as expected. Additionally, data scientists may need to adjust the modeling technique or the model parameters to optimize performance.
In summary, data modeling is a critical step in the data science process that involves developing mathematical or statistical models that can be used to make predictions or gain insights from the data. By taking a systematic and thoughtful approach to data modeling, data scientists can develop models that accurately represent the underlying relationships and patterns in the data and provide valuable insights to stakeholders.
6. Data Model Evaluation
Data model evaluation is a critical step in the data science process that involves assessing the performance of a predictive model on new or unseen data. The goal of model evaluation is to determine how well the model is likely to perform in the real world and to identify any potential issues or limitations that may need to be addressed.
The first step in model evaluation is to partition the data into a training set and a test set. The training set is used to train the model, while the test set is used to evaluate its performance. The test set should be representative of the data that the model is likely to encounter in the real world.
Once the model has been trained on the training set, it is applied to the test set to generate predictions. The performance of the model is then evaluated using a range of evaluation metrics, such as accuracy, precision, recall, F1 score, or area under the curve (AUC).
Evaluation metrics provide a quantitative measure of the performance of the model. For example, accuracy measures the proportion of correctly classified instances, while precision measures the proportion of true positives among all instances predicted to be positive. Different evaluation metrics may be appropriate for different types of problems or datasets.
In addition to evaluation metrics, data scientists may also use visualizations, such as confusion matrices, ROC curves, or precision-recall curves, to gain a better understanding of the performance of the model.
It’s important to note that model evaluation is an iterative process. Data scientists may need to revisit earlier stages of the process, such as data preparation or feature engineering, if the model is not performing as expected. Additionally, data scientists may need to adjust the modeling technique or the model parameters to optimize performance.
6. Data Model Evaluation
Data model deployment is an essential step in the data science process, which involves taking the trained machine learning model and making it available for use in the production environment. The deployment process involves several steps that ensure that the model can perform efficiently and effectively in real-world scenarios. In this write-up, we will discuss the key aspects of data model deployment in data science.
Data model deployment is critical in data science because it helps to turn the insights gained from data analysis into actionable solutions. The process ensures that the models created during the data science process can be deployed in real-world scenarios to make data-driven decisions. By deploying a model, data scientists can enable decision-makers to use the results of data analysis to automate processes, optimize systems, and improve business outcomes.
Types Of Data Science Tools
There are many types of data science tools that are available to help data scientists perform their work. Data science tools play a critical role in enabling data scientists to extract insights from complex data sets and make data-driven decisions. The choice of tools depends on the specific needs of the project, as well as the expertise of the data science team.
Here are some of the most common types of data science tools:
1. Data Collection And Management Tools
These tools help data scientists to collect and manage large amounts of data from various sources. Data science projects usually deals with large volumes of data that needs suitable database and Database Management System (DBMS).
Examples of data collection and management tools include Apache Hadoop, Apache Spark, and SQL databases like MySQL and PostgreSQL.
2. Data Visualization Tools
These tools help data scientists to create visual representations of data, such as charts, graphs, and maps. Data visualization tools help data scientists create interactive and insightful visualizations of complex data. Examples of data visualization tools include Tableau, Power BI, and D3.js.
3. Data Analysis And Modelling Tools
These tools help data scientists to analyze and model data to derive insights and make predictions. Examples of data analysis and modelling tools include R, Python, and SAS.
4. Machine Learning And Deep Learning Tools
These tools help data scientists to develop and train machine learning and deep learning models to perform tasks such as image recognition, natural language processing, and predictive analytics. Examples of machine learning and deep learning tools include TensorFlow, PyTorch, and scikit-learn.
5. Data integration and ETL Tools
Data integration and ETL (Extract, Transform, Load) tools tools help data scientists to integrate and transform data from various sources into a format that is suitable for analysis. Examples of data integration and ETL tools include Apache Nifi, Talend, and Apache Kafka.
6. Cloud-Based Data Science Platforms
These tools provide an end-to-end solution for data science, from data collection and management to analysis and visualization. Examples of cloud-based data science platforms include Google Cloud Platform, Amazon Web Services, and Microsoft Azure.
7. Programming Languages
Programming languages are the backbone of data science. Popular programming languages used in data science include Python, R, SQL, and MATLAB. Python and R are the most commonly used languages for data analysis and machine learning.
8. Data Cleaning And Pre-processing Tools
Data cleaning and pre-processing tools help data scientists prepare data for analysis by cleaning, formatting, and transforming it. Some popular data cleaning and pre-processing tools include OpenRefine, Trifacta, and DataWrangler.
9. Statistical Analysis Tools
Statistical analysis tools are used for exploring data, identifying patterns, and making predictions. Some popular statistical analysis tools include SAS, SPSS, and Stata.
10. Natural Language Processing Tools
Natural language processing tools are used to analyze and interpret human language. Some popular natural language processing tools include NLTK, SpaCy, and Stanford NLP.
Introduction To Data Science
Applications Of Data Science
Data Science is a rapidly growing field that involves extracting insights and knowledge from data using scientific and statistical techniques.
Data science has various applications, including business intelligence, predictive modelling, fraud detection, recommendation systems, natural language processing, image and speech recognition, personalized medicine, and many more.
Its use is becoming increasingly prevalent in various industries, including finance, healthcare, retail, and manufacturing, to make informed decisions, optimize processes, and improve products and services.

1. Business Intelligence:
Data Science can be used to analyze large datasets to identify patterns, trends, and relationships that can help businesses gain insights into their operations, customers, and market trends. This can help businesses make informed decisions to optimize their operations, improve their performance, and gain a competitive advantage.
2. Predictive Analytics
Predictive Analytics is a type of Data Science that uses statistical algorithms and machine learning models to analyze historical data and make predictions about future outcomes. For example, it can be used to predict customer behavior, sales trends, or product demand. This can help businesses make informed decisions and optimize their operations to improve their performance.
3. Fraud Detection
Fraud Detection is another application of Data Science that uses statistical algorithms and machine learning models to identify patterns of fraudulent behavior in large datasets. For example, it can be used to detect credit card fraud, insurance fraud, or healthcare fraud. This can help businesses or government agencies detect and prevent fraudulent activities, which can save them millions of dollars.
4. Healthcare
Data Science can be used in healthcare to analyze patient data and develop personalized treatment plans. For example, it can be used to identify disease trends, predict patient outcomes, or develop personalized treatment plans based on the patient’s medical history and genetic profile. This can improve patient outcomes and reduce healthcare costs.
5. Social Media Analytics
Social Media Analytics is another application of Data Science that uses statistical algorithms and machine learning models to analyze social media data. For example, it can be used to analyze customer behavior, brand sentiment, or market trends. This can help businesses gain insights into their customers’ preferences and behavior and develop targeted marketing campaigns.
6. Recommendation Systems
Recommendation Systems are another application of Data Science that uses machine learning algorithms to develop personalized recommendations for customers based on their behavior, preferences, and purchase history. For example, it can be used to recommend products to customers based on their previous purchases or recommend movies to users based on their viewing history. This can improve customer engagement and satisfaction.
7. Image And Speech Recognition
Image and Speech Recognition are other applications of Data Science that use machine learning algorithms to develop systems that can recognize and understand images and speech. For example, it can be used to develop self-driving cars that can recognize and respond to traffic signals or develop virtual assistants that can understand and respond to user commands. This can improve efficiency, safety, and convenience in various applications.
Artificial Intelligence And Data science
Artificial Intelligence (AI) and Data Science are two closely related fields that have gained a lot of attention in recent years. Both of these fields deal with data and aim to make sense of it to drive better decision-making and predictions.
AI involves the development of intelligent machines that can simulate human intelligence and perform tasks that typically require human intelligence, such as recognizing speech, identifying images, and playing games. AI relies heavily on algorithms and statistical models to make decisions and predictions.
On the other hand, Data Science involves the extraction, cleaning, analysis, and interpretation of large amounts of data. Data Science techniques are used to identify patterns, make predictions, and inform business decisions. Data Science involves a combination of statistical analysis, machine learning, and data visualization.
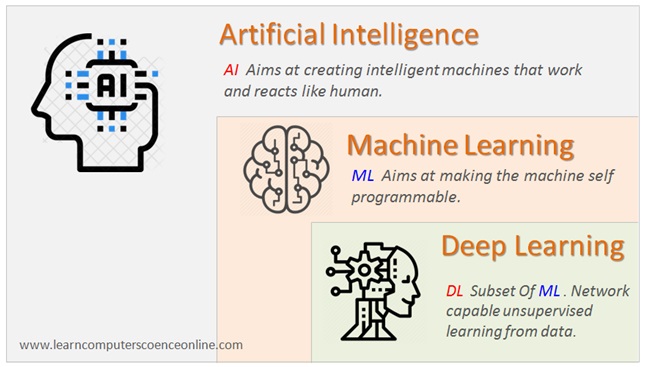
While AI and Data Science are distinct fields, they are often used together to develop intelligent systems that can make predictions and automate decision-making. For example, AI algorithms can be used to develop predictive models that can be used by Data Scientists to gain insights into business operations or predict consumer behaviour.
Overall, AI and Data Science are both essential for businesses to stay competitive in today’s data-driven world. The ability to leverage data and use it to inform decisions is becoming increasingly important, and AI and Data Science provide the tools and techniques needed to do so effectively.
Common Job Profiles And Titles In Data Science
There are several job roles and titles in the field of data science, each with its own unique set of responsibilities and requirements. These are just a few examples of the many job roles available in data science. The specific responsibilities and requirements of each job will vary depending on the organization and industry.
Some common job titles in data science include:

1. Data Scientist
A data scientist is a professional who uses data science methods and tools to extract insights and knowledge from data. Data scientists are responsible for analyzing large and complex data sets, building predictive models, and developing algorithms to solve business problems. They work with various stakeholders in an organization to understand their requirements and provide data-driven solutions.
In summary, data science is the field, while a data scientist is a professional who uses the techniques and tools from data science to solve business problems.

2. Data Analyst
A data analyst is a professional who uses their skills in statistics, programming, and data analysis to extract insights from data and provide meaningful information to help organizations make informed decisions. Data analysts collect, process, and perform statistical analyses on data sets, often using specialized software tools and programming languages. They work with both structured and unstructured data, and may be involved in tasks such as data cleaning, data visualization, and report generation.
Data analysts are employed in a wide range of industries, including healthcare, finance, marketing, and government, and may work in-house or as consultants.
3. Machine Learning Engineer
A machine learning engineer is a professional who develops and implements algorithms and models for machine learning applications. They are responsible for designing, building, and deploying machine learning systems that can learn from data and make predictions or decisions without being explicitly programmed.
Machine learning engineers work with large and complex data sets, and use a variety of tools and techniques to preprocess and analyze the data, train and test models, and optimize performance.
They typically have a strong background in computer science, mathematics, and statistics, and are proficient in programming languages such as Python, R, and Java. They work closely with data scientists and data analysts to develop and deploy machine learning solutions that can be integrated into production systems, and are often involved in tasks such as data cleaning, feature engineering, model selection, and hyperparameter tuning.
Machine learning engineers are employed in a wide range of industries, including finance, healthcare, e-commerce, and technology.
4. Business Intelligence Analyst
A business intelligence (BI) analyst is a professional who uses data to inform and drive business decisions. They are responsible for collecting, analyzing, and interpreting data from various sources to provide insights that help organizations make strategic decisions. BI analysts typically work with large data sets and use specialized tools and technologies to extract insights, such as SQL, data visualization tools, and BI platforms.
The role of a BI analyst involves designing and creating reports, dashboards, and visualizations that communicate insights to stakeholders. They also monitor key performance indicators (KPIs) and track trends to identify areas for improvement. BI analysts work closely with business leaders to understand their goals and objectives, and provide data-driven recommendations to help achieve them.

BI analysts must have strong analytical skills and be proficient in data visualization tools and techniques. They must also have excellent communication skills to effectively communicate complex data and insights to stakeholders. BI analysts are employed in a wide range of industries, including finance, healthcare, e-commerce, and technology.
5. Data Engineer
A data engineer is a professional who is responsible for designing, building, and maintaining the infrastructure that enables organizations to store, process, and analyze large volumes of data. They work with big data technologies and tools, such as Hadoop, Spark, and NoSQL databases, to build and maintain data pipelines that move data from various sources into a centralized data warehouse or data lake.
Data engineers are responsible for ensuring that data is accurate, consistent, and accessible to other members of the organization. They work with data scientists, data analysts, and business analysts to understand their data requirements and develop data models and architectures that meet their needs. They are also responsible for monitoring and maintaining the performance and scalability of data systems and ensuring that data security and privacy standards are met.
Data engineers must have a strong background in computer science and data management, as well as knowledge of big data technologies and programming languages such as Python and Java. They also need to have strong problem-solving skills, as they often need to troubleshoot issues with data pipelines and systems. Data engineers are employed in a wide range of industries, including finance, healthcare, e-commerce, and technology.
6. Big Data Engineer
A big data engineer is a professional who specializes in designing, building, and maintaining the infrastructure required to process and analyze large volumes of data. They work with big data technologies and tools, such as Hadoop, Spark, and NoSQL databases, to build and maintain data pipelines that move data from various sources into a centralized data warehouse or data lake.
Big data engineers are responsible for ensuring that data is accurate, consistent, and accessible to other members of the organization. They work with data scientists, data analysts, and business analysts to understand their data requirements and develop data models and architectures that meet their needs. They are also responsible for monitoring and maintaining the performance and scalability of data systems, and ensuring that data security and privacy standards are met.
Big data engineers must have a strong background in computer science and data management, as well as expertise in big data technologies and programming languages such as Python, Java, and Scala. They also need to have strong problem-solving skills, as they often need to troubleshoot issues with data pipelines and systems. Big data engineers are employed in a wide range of industries, including finance, healthcare, e-commerce, and technology.
7. Database Administrator
A database administrator (DBA) is a professional who is responsible for the installation, configuration, maintenance, and security of an organization’s databases. They ensure that data is stored securely, and that data is available to users when needed. They are responsible for monitoring and optimizing the performance of databases, ensuring that backups and recovery procedures are in place, and managing user access and permissions.
DBAs work with a variety of database management systems (DBMS) such as Oracle, MySQL, and Microsoft SQL Server. They are responsible for designing and implementing databases, as well as maintaining the database schema and data dictionary. They also work closely with other members of the organization, such as developers and data analysts, to ensure that the database meets their needs.
DBAs must have a strong background in database management, as well as expertise in database technologies and programming languages such as SQL. They also need to have strong problem-solving skills, as they often need to troubleshoot issues with databases and systems. DBAs are employed in a wide range of industries, including finance, healthcare, e-commerce, and technology.
8. Data Architect
A data architect is a professional who is responsible for designing and maintaining the overall structure of an organization’s data assets. They work with stakeholders to understand their data requirements and design solutions that meet their needs. They are responsible for designing and maintaining data models, creating data dictionaries, and defining data standards and policies.
Data architects work closely with other members of the organization, such as data engineers and database administrators, to ensure that data is stored and managed effectively. They are also responsible for designing data integration and migration strategies, and ensuring that data is secured and compliant with relevant regulations and policies.
Data architects must have a strong background in data management and architecture, as well as expertise in data modeling and database design. They must also have excellent communication skills to effectively communicate with stakeholders and other members of the organization. Data architects are employed in a wide range of industries, including finance, healthcare, e-commerce, and technology.
Introduction To Data Science

